一、堆排序
堆可以用来实现 n 个元素的排序,所需时间为 O ( n l o g n ) O(nlog n) O(nlogn)。先用 n 个待排序的元素来初始化一个大根堆。然后从堆中逐个提取元素。结果,这些元素按非递增顺序排序。初始化的时间为 O ( n ) O(n) O(n),每次删除的时间为 O ( l o g n ) O(log n) O(logn),因此总时间为 O ( n l o g n ) O(nlog n) O(nlogn)。
#pragma once
#include "heap.h"
template<typename T, typename Pred = std::greater<T>>
void heapSort(T arr[], int arrayLength)
{
heap<T, Pred> h;
h.initialize(arr, arrayLength);
for (int i = 0; i < arrayLength; ++i)
{
arr[i] = h.top();
h.pop();
}
}
二、机器调度
这里的机器调度问题和前面的工厂仿真类似。一个工厂具有 m 台一样的机器,我们有 n 个任务需要处理。假设作业 i 的处理时间为
t
i
t_i
ti,这个时间包括把作业放入机器和从机器上取下的时间。所谓调度是指按作业在机器上的运行时间分配作业,使得:
① 一台机器在同一时间内只能处理一个作业。
② 一个作业不能同时在两台机器上处理。
③ 一个作业 i 的处理时间是
t
i
t_i
ti个时间单位。
假如每台机器在0时刻都是可用的,完成时间或调度长度是指完成所有作业的时间。在一个非抢先调度中,一项作业 i 在一台机器上处理,从时刻 s i s_i si开始,到时刻 s i + t i s_i+t_i si+ti结束。
假设在3台机器处理7个作业,对应的处理时间分别为(2, 14, 4, 16, 6, 5, 3),处理时序如图:

图中的调度是一个在给定处理时间前提下最小完成时间的调度。为了认识到这一点,注意,处理时间的总和为50。因此,三台机器调度都最少需要
⌈
50
3
⌉
=
17
\lceil\frac{50}{3}\rceil=17
⌈350⌉=17。
调度问题是一个NP-复杂问题,相关的介绍可以参考P问题、NP问题、NPC问题(NP完全问题)、NPH问题和多项式时间复杂度。在我们的调度问题中,采用了一个简单调度策略,称为最长处理时间(LPT),它的调度长度是最优调度长度的 4 3 − 1 3 m \frac{4}{3}-\frac{1}{3m} 34−3m1。在 LPT 算法中,作业按处理时间的递减顺序排列。当一个作业需要分配时,总是分配给最先变为空闲的机器。没有固定的分配方案。
1、使用堆建立 LPT
使用堆来建立 LPT调度方案的时间性能为 O ( n l o g n ) O(nlog n) O(nlogn)。当 n ≤ m n\le m n≤m时,只需要将作业 i 在0~ t i t_i ti 时间内分配给机器 i 来处理。当 n > m n \gt m n>m时,可以首先利用堆排序将作业按处理时间递增排序排列。为了建立 LPT 调度方案,作业按相反次序进行分配。
为了决定将一个作业分配给哪一台机器,必须知道哪台机器最先空闲。为此,维持一个 m 台机器的小根堆,元素类型为 machine,它有数据成员可用时间和机器编号。pop函数用于获取下一个最先可用的机器。当机器的可用时间增加后,需要再次插入小根堆。
类似地,我们使用类 job 表示作业,包含编号和时长两个数据成员。作业同样需要保存在堆中,但是是大根堆。
2、实现
(1)修改heap
前面实现的堆有些问题,其实并没有真正的支持比较函数的设置。我们需要修改后默认构造函数及其调用:
inline heap<T, Predicate>::heap(int capacity,const Predicate& pred):
comp(pred)
{
elements = new T[capacity];
this->capacity = capacity;
}
template<typename T, typename Predicate>
inline void heap<T, Predicate>::initialize(T* origin, int arrayLength)
{
auto tempHeap = new heap(arrayLength * 2, comp);
...
}
(2)job
job 类为作业类,需要所有文件都可以访问:
// job.h
#pragma once
struct Job
{
int id;
int totalTime;
};
(3)调度类头文件
// JobSchedule.h
#pragma once
class Job;
class JobSchedule
{
public:
void schedule(Job* jobs, int jobNum, int machineNum);
};
(4)机器类
// JobSchedule.cpp
struct machine
{
int id;
int availableTime = 0;
};
(5)调度功能
// JobSchedule.cpp
#include "JobSchedule.h"
#include "Job.h"
#include "../heap.h"
#include <iostream>
#include <functional>
using namespace std;
void JobSchedule::schedule(Job* jobs, int jobNum, int machineNum)
{
if (jobNum < machineNum)
{
cout << "schedule each job on a different machine." << endl;
return;
}
auto machineComp = [](machine& left, machine& right) {return left.availableTime < right.availableTime; };
heap<machine, decltype(machineComp)> machineHeap(10, machineComp);
for (int i = 1; i <= machineNum; ++i)
{
machineHeap.push({ i, 0 });
}
auto jobComp = [](Job& left, Job& right) {return left.totalTime >= right.totalTime; };
heap<Job, decltype(jobComp)> jobHeap(10, jobComp);
jobHeap.initialize(jobs, jobNum);
while (!jobHeap.empty())
{
auto curJob = jobHeap.top();
jobHeap.pop();
auto curMachine = machineHeap.top();
machineHeap.pop();
cout << "schedule Job " << curJob.id << " on machine " << curMachine.id << " from " << curMachine.availableTime
<< " to " << curMachine.availableTime + curJob.totalTime << endl;
curMachine.availableTime += curJob.totalTime;
machineHeap.push(curMachine);
}
}
3、测试
#pragma once
#include "JobSchedule.h"
#include "Job.h"
void test()
{
JobSchedule schedule;
Job jobs[] = { {1, 2}, {2, 14}, {3, 4}, {4, 16}, {5, 6}, {6, 5}, {7, 3} };
schedule.schedule(jobs, sizeof(jobs) / sizeof(Job), 3);
}
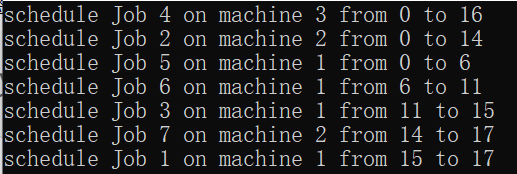
和我们前面图表中的结果是一致的。







