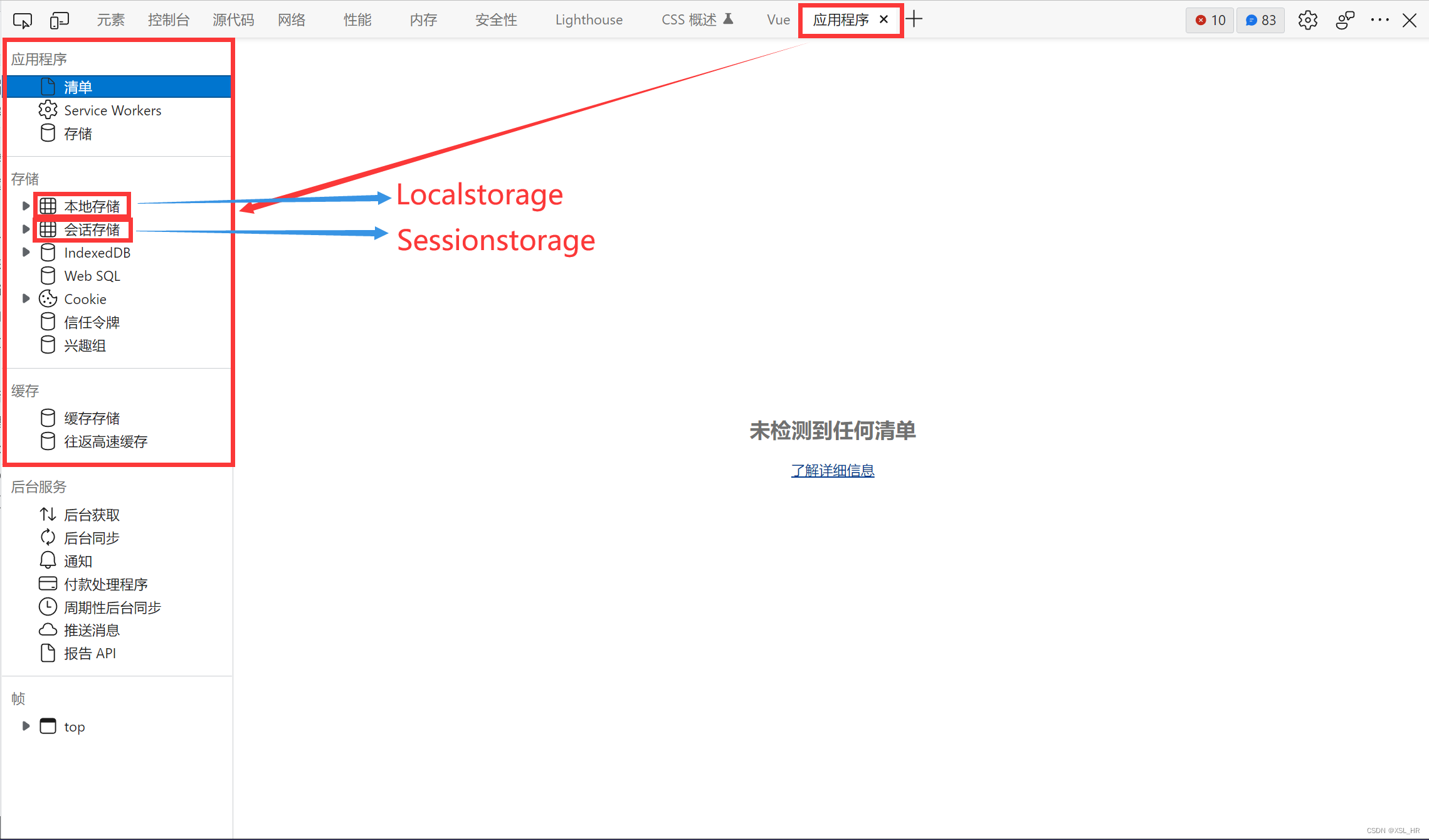
…
更多知识尽在此专栏中!

- I am a great believer in luck, and I find that the harder I work, the more I have of it.
- 我很相信运气,事实上我发现我越努力,我的运气越好。
文章目录
- 📘前言
- 📘正文
- 📖认识堆
- 📖实现堆
- 📃结构
- 📃入堆
- 📃出堆
- 📃建堆算法
- 📖使用堆
- 📃堆排序
- 📃Top-K 问题
- 📖源码
- 📘总结
📘前言
堆(heap)是计算机科学中一类特殊的数据结构的统称,堆通常是一个可以被看做一棵树的数组对象,因此堆常常是通过数组的形式来实现的,不过堆在实现时必须遵守两个原则
- 要么是
大根堆(大堆),要么是小根堆(小堆) 堆总是一棵完全二叉树
堆在实现时的基本功能有 入堆、出堆、查看堆顶元素及大小、判空 等,不过堆通常不单独使用,常常是作为一种辅助结构来处理现实中的问题,比如堆排序和Top-K问题
可以把堆进行理想化处理,就比如下图中的谷堆,就是一个非常标准的堆

关于堆的详细介绍还得接着往下看,相信你在看完后能学到很多干货!
📘正文
📖认识堆
想要认识堆,就要清楚堆的两条原则
原则一:
堆必须是大根堆(大堆)或者小根堆(小堆)
大根堆(大堆):即堆中所有元素的父亲都要比自己大(除了堆顶元素,堆顶元素没有父亲)小根堆(小堆):与大堆相反,堆中的所有元素的父亲都要比自己小(除了堆顶元素,堆顶元素没有父亲)通俗来说,就是整个
堆都要呈现出一种有序性,这种有序是 纵向的有序 ,可以通过现实中的实际例子举例,假设小明今年18岁,而他有一个16岁的亲弟弟小黑,以及一个24岁的堂姐小红,那么此时小明的家谱可以表示如下
显然,小明的爷爷是 >> 其父亲 >> 自己的,而同层间的兄弟姊妹关系不讲究,纵向是绝对有序的,这不符合了堆的第一条原则吗?事实上,将上图规范化,就能得到一个堆的逻辑结构图


原则二:
堆总是一棵完全二叉树
完全二叉树指二叉树的前n-1层是满的,最后一层可以不满,但是要求树的节点从左到右都是连续的(递增或相等),比如上图中的就是一棵完全二叉树,判断是否为完全二叉树的关键为节点是否连续
知道这两条原则后,堆就算是入门了,不过堆在计算机中并不是直接以完全二叉树的形式存储的,而是以这种形式[68, 40, 44, 18, 16, 24],没错,堆的真实物理结构是数组,逻辑结构(完全二叉树)只是为了让我们更好的理解堆,因此我们在实现堆时,需要借助顺序结构,画图理解时,可以画成完全二叉树的形式
Tips:堆为何必须是完全二叉树?
- 因为完全二叉树是必然连续的,完美符合数组连续存储的特性
- 可以避免不必要的索引浪费,这是提高效率的关键
- 后续在取堆顶元素、入堆、出堆时也比较直观
📖实现堆
📃结构
堆底层是顺序表,因此在定义堆结构时,可以复用顺序表的代码(当然函数要改个名字)
typedef int HPDataType; //堆的元素类型
typedef struct HeapInfo
{
HPDataType* data; //数据域
int size; //堆的有效元素数
int capacity; //堆的容量,方便后续进行扩容
}HP;
堆的初始化、销毁、打印,非常简单,这里就不再做过多介绍,忘记的同学可以去看看我以前写的关于顺序表的文章

📃入堆
入堆前首先要先对数组容量进行检查,判断是否需要扩容,这也是个老朋友了,确认空间够大后,将目标数据插到堆底(完全二叉树末尾处),然后向上调整即可
- 检查容量可以判断
size是否等于capacity - 堆底(完全二叉树末尾处)就是数组中
size为下标的地方,插入成功后,size要+1 size初始化时为0,因此size的值还表示当前堆中的有效元素数
堆的精髓在于向上调整和向下调整,学好了就能掌握堆了,因为 堆的核心思想在于不断调整 ,首先介绍比较简单的向上调整
堆的向上调整,调整分为如下几步
- 假设当前插入的元素处(节点)为孩子,那么需要找到他的父亲节点,计算公式为
parent = (child - 1) / 2- 通过所得到的父亲与孩子(都是下标),判断二者所代表的值大小,假设当前要建大堆,如果孩子比父亲大,那么就需要交换孩子与父亲的值,孩子变成父亲,向上更新父亲;如果不满足条件,则不需要进行调整,直接结束循环即可
- 假设这个新插入的元素(节点)很大,甚至能直接取代堆顶元素(根节点),那么循环的条件就要设为
孩子 > 0简言之,
向上调整的关键在于为新插入的元素找到合适的位置,使得堆满足原则一,所有父亲大于孩子(大堆),有点像打擂台,有能力的人就向上走,这里准备了一个动图,可以很好的展示这个过程

入堆及向上调整的代码如下
//向上调整,根据孩子找父亲
void AdjustUp(HPDataType* pa, int n, int child)
{
assert(pa);
//大堆:父亲比孩子都大
//小堆:父亲比孩子都小
int parent = (child - 1) / 2;
while (child > 0)
{
//大堆,孩子比父亲大,就调整
//如果条件为假,说明此位置是合法的
if (pa[child] > pa[parent])
{
Swap(&pa[child], &pa[parent]);
child = parent; //孩子移动
parent = (child - 1) / 2; //父亲更新
}
else
break;
}
}
void HeapPush(HP* ph, HPDataType x) //入堆
{
assert(ph);
//考虑扩容
if (ph->size == ph->capacity)
{
HPDataType newcapacity = ph->capacity == 0 ? 4 : ph->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(ph->data, sizeof(HPDataType) * newcapacity);
if (!tmp)
{
perror("realloc fail");
exit(-1);
}
ph->capacity = newcapacity;
ph->data = tmp;
}
//入堆,直接尾插,然后向上调整
ph->data[ph->size++] = x;
AdjustUp(ph->data, ph->size, ph->size - 1);
}
注意:
- 在进行向上调整时,正确的找到孩子及其对应父亲是关键
- 无论是左孩子还是右孩子,都可以通过
parent = (child - 1) / 2来计算父亲- 交换值时,需要传地址,因为形参只是实参的一份临时拷贝
- 代码中的交换函数很简单,这里没有展示
- 调整的核心是
为元素找到合适的位置(这个思想很重要)
- 所谓合适的位置就是必须满足原则一,成为大堆或小堆
📃出堆
出堆,出的是堆顶元素,即下标为0处的元素,因为对于数组来说,头删是十分不利的,因此我们这里学要借助一个小技巧:
- 将堆顶元素与堆底元素交换,然后将
size - -,这样就间接删除了原堆顶元素 - 元素交换后,
堆的整体有序性将被打破,此时需要借助向下调整函数来矫正堆
显然,这里的关键在于向下调整函数,与向上调整找父亲不同,向下调整是找大孩子或小孩子(对应大堆或小堆),在找孩子时还需要特别注意越界问题
向下调整的步骤
- 确认向下调整的父亲,这里是删除堆顶元素,所以父亲是0
- 根据公式计算出目标孩子,假设左孩子为目标孩子,后续会进行判断验证
- 左孩子的计算公式
leftChild = parent * 2 + 1- 右孩子的计算公式
rightChild = parent * 2 + 2- 左右孩子间隔为 1,判断验证起来也很容易
- 判断左孩子是否为目标孩子,如果不是,
child + 1修改为右孩子,是的话就用左孩子
- 如果左孩子为最后一个孩子,那么此时进行判断验证是非法的,因为会涉及到越界问题,因此在判断验证前,需要先判断右孩子是否存在,即
child + 1 < n- 判断当前孩子值与父亲值间的关系,假设建大堆,如果当前孩子值大于父亲值,那么就进行值交换,父亲变成孩子,重新假设目标孩子;如果不满足条件,跳出循环即可
- 循环结束条件为
child < n,当child >= n时,说明此时的父亲已经是当前堆中的最小父亲了(有孩子的才叫父亲)
向下调整比向上调整还麻烦,不过这东西的效率是极高的,后面介绍堆的应用场景时就明白了,向下调整核心仍然是为当前元素找到合适位置,不过因为孩子有两个,且他们之间的大小关系不明确,因此在确定孩子时需要多判断一下,同样的准备了动图,给大家看看演示下这个过程

向下调整逻辑是罗嗦了点,不过代码还是比较少的
void AdjustDown(HPDataType* pa, int n, int parent) //向下调整
{
assert(pa);
//大堆,向下调整,需要找出大孩子,然后比较是否需要交换
int child = parent * 2 + 1; //假设左孩子为大孩子
while (child < n)
{
//必须有右孩子才能进行判断
if ((child + 1) < n && pa[child + 1] > pa[child])
child++;
if (pa[child] > pa[parent])
{
Swap(&pa[child], &pa[parent]);
parent = child;
child = parent * 2 + 1; //循环
}
else
break;
}
}
void HeapPop(HP* ph) //出堆
{
assert(ph);
assert(!HeapEmpty(ph));
//出的是堆顶的元素
//先把堆顶和堆底元素交换,然后向下调整
Swap(&ph->data[0], &ph->data[ph->size - 1]); //交换
ph->size--; //有效元素-1
AdjustDown(ph->data, ph->size - 1, 0); //向下调整
}
注意:
- 出堆的前提是有元素可出,因此多加了一个断言,调用了判空函数
- 判空函数其实就是判断
size是否为0- 交换是堆顶与堆底进行交换,然后
size- -
- 堆顶元素在
0处,堆底元素在size - 1处- 向下调整时,先是假设左孩子为目标孩子,之后再进行判断验证
- 当然,判断验证的前提是右孩子必须存在,因此条件
child + 1 < n是不能少的- 向下调整的核心思想也是
为元素找到合适的位置
- 原则一,不能少
📃建堆算法
建堆算法是指直接传入一个数组,通过这个数组生成对应的大堆(小堆),建堆的步骤如下:
- 开辟一块足够大的空间,作为
堆空间 - 拷贝数组中的所有元素至新空间内
- 通过两种不同的方式进行
堆调整- 向上调整(效率低)
- 向下调整(效率高)
| 两种调整性能比对 | 时间复杂度 | 数据量:100万 | 数据量:1亿(无序) | 数据量:1亿(有序) |
|---|---|---|---|---|
| 向上调整建堆 | F(N) = N*logN | 耗时29毫秒 | 耗时3036毫秒 | 耗时2310毫秒 |
| 向下调整建堆 | F(N) = N - log(N + 1) | 耗时22毫秒 | 耗时2372毫秒 | 耗时1997毫秒 |
推荐使用向下建堆,因为后续的堆排序和Top-K用的都是向下调整
向上调整建堆代码:
void HeapCreat(HP* ph, HPDataType* pa, int n) //构建堆
{
//建堆有两种方式
//1.向上调整
//2.向下调整
assert(pa);
//开辟一块空间
HPDataType* ptmp = (HPDataType*)malloc(sizeof(HPDataType) * n);
assert(ptmp);
ph->data = ptmp;
ph->size = ph->capacity = n;
//将数据拷贝至开辟空间中
ph->data = memcpy(ph->data, pa, sizeof(HPDataType) * (n - 1));
//向上调整
for (int i = n - 1; i > 0; i--)
AdjustUp(ph->data, i, i - 1);
}
向下调整建堆算法:
void HeapCreat2(HP* ph, HPDataType* pa, int n) //构建堆
{
//建堆有两种方式
//1.向上调整
//2.向下调整
assert(pa);
//开辟一块空间
HPDataType* ptmp = (HPDataType*)malloc(sizeof(HPDataType) * n);
assert(ptmp);
ph->data = ptmp;
ph->size = ph->capacity = n;
//将数据拷贝至开辟空间中
ph->data = memcpy(ph->data, pa, sizeof(HPDataType) * (n - 1));
//向下调整,建堆算法
int parent = (n - 1 - 1) / 2;
for (int i = parent; i >= 0; i--)
AdjustDown(ph->data, n - 1, i);
}
关于堆的其他操作:取堆顶元素、当前堆的有效元素数、判断堆是否为空等,都是很简单的功能,基本逻辑和顺序表一样,忘记的可以去看看以前的博客

📖使用堆
有了堆我们可以干什么呢?
- 进行高效的排序和名次选拔
排序即堆排序,是一种效率极高的排序,与希尔、快排、归并等位于第一梯队,堆排序的核心在于向下调整,因为它的时间复杂度很低,因此整体排序效率就高;除了排序以外,堆还可以帮我们选出指定前 K 位数据,比如在10亿中找出最高的十个人,这就是Top-K问题
📃堆排序
堆排序,需要注意的是升序建大堆,降序建小堆,步骤如下:
- 假设求升序,先通过建堆算法建立一个
大堆 - 因为
大堆中的堆顶元素总是最大的数,将这个数换到堆底(沉底) 向下调整堆,重新选出次大的数(此时调整的范围 - 1)- 重复上述步骤,直到遍历
数组大小 - 1次,最后一个数没必要比了
长话短说,堆排序运用了堆顶元素总是最大 或 最小值这一特点,将这个值沉到堆底,调整范围不断缩小,不断选出最大值 或 最小值,如此重复即可完成排序
void HeapSort(HPDataType* pa, int n) //堆排序
{
assert(pa);
//升序,建大堆,降序,建小堆
//注意:对数据进行排序,数组就是一个天然的堆,调整下就行了
//均采用向下调整建堆
int i = (n - 1 - 1) / 2;
for (; i >= 0; i--)
AdjustDown(pa, n, i);
//大堆(升序),此时堆顶元素就是最大值,将其沉底,然后调整堆
for (int i = 0; i < n - 1; i++)
{
Swap(&pa[0], &pa[n - 1 - i]); //交换
AdjustDown(pa, n - 1 - i, 0); //调整
}
}
注意
- 什么场景下用什么堆,这是很关键的事,一定要考虑清楚
📃Top-K 问题
Top-K 问题就像是堆排序的变种,求最大的前K个数时,需要小堆,求最小的前K个数时,需要大堆。至于Top-K为何如此奇怪,还得先看看求解步骤:
- 假设求前
K个最小的值,根据传入的K值,创建大小为K的堆 - 将数组中的
K个元素拷贝值堆中,然后调整建大堆 - 从第
K个元素开始(K是元素个数,对应下标 - 1),如果数组值小于此时的堆顶元素值(堆的最大值),就将这个数组值换至堆顶处,向下重新调整堆 - 如此重复,直到将数据中的
n-K个数组值遍历比较完
长话短说,Top-K 也是通过堆的特性:大堆顶为最大值,小堆顶为最小值,巧妙解决了需求。
举个例子,存在数组[3,5,1],假设求最小的前两个数,建立大堆[5,3],此时的数组值 1 小于堆顶值 5,交换,调整,得到堆[3,1],此时通过排序优化,就可以得到最小的前两个数 1、3
- 原理:将
大堆中的最大值不断刷掉,剩下的自然就是最小的K个数了 - 不过在求出目标数后,
不一定有序,需要稍微排下序
void TopK(HPDataType* pa, int n, int k) //TopK问题
{
assert(pa);
//最大,小堆
//最小,大堆
HP h;
HeapInit(&h);
int* tmp = (int*)malloc(sizeof(int) * k);
assert(tmp);
h.data = tmp;
h.size = h.capacity = k;
memcpy(h.data, pa, sizeof(int) * k);
int parent = (k - 1 - 1) / 2;
for (int i = parent; i >= 0; i--)
AdjustDown(h.data, k, i);
int i = k;
while (i < n)
{
//现在是大堆,比较条件是数组元素小于堆顶元素,取的是最小的前k个数
if (pa[i] < h.data[0])
{
Swap(&pa[i], &h.data[0]);
AdjustDown(h.data, k - 1, 0);
}
i++;
现在是小堆,比较条件是数组元素大于堆顶元素,取的是最大的前k个数
//if (pa[i] > h.data[0])
//{
// Swap(&pa[i], &h.data[0]);
// AdjustDown(h.data, k, 0);
//}
//i++;
}
//排序一下,显示效果更好
HeapSort(h.data, k);
HeapPrint(&h);
HeapDestroy(&h);
}
注意
- 跟堆排序一样,需要注意适用场景,千万不能弄错,不然会陷入一个怪圈的
📖源码
源码放在码云(Gitee上了),感兴趣的同学可以点击这里跳转

📘总结
以上就是本篇文章的所有内容了,我们从什么是堆入手,探讨了堆的具体实现,最后还举例了堆运用的实际例子,相信你在看完后一定能收获到很多干货!
如果你觉得本文写的还不错的话,期待留下一个小小的赞👍,你的支持是我分享的最大动力!
如果本文有不足或错误的地方,随时欢迎指出,我会在第一时间改正

…
相关文章推荐
数据结构 | 顺序表
数据结构 | 单链表
数据结构 | 栈和队列





![[附源码]计算机毕业设计的4s店车辆管理系统Springboot程序](https://img-blog.csdnimg.cn/0832d5be63614c3ca2e2458be749311b.png)