1. 简介
-
完全二叉堆可用于实现优先队列。
-
当然,使用数组或列表也可以实现优先队列,但通常需要先将其中的所有数据进行排序才可,即首先维护一种全序关系。
-
但事实上,优先队列只要能够确定全局优先级最高的 entry 即可,而不要求全局先有序。
-
完全二叉堆无需先对所有数据进行排序即可确定全局优先级最高的 entry,因此更加适用于优先队列的实现。
2. 定义
-
设节点总数为 n n n,则堆的高度为 O ( log n ) O(\log n) O(logn),插入操作、删除优先级最高的 entry 的操作的时间复杂度均为 O ( log n ) O(\log n) O(logn)。
-
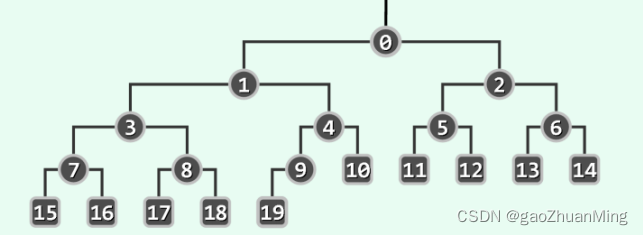
假设自顶向下对堆的每一层、从左到右对每个节点进行编号,且编号从 0 开始,则有:
- 假设节点 x x x 的编号为 i i i,且存在左右孩子,则 x x x 的左孩子的编号为 2 i + 1 2i+1 2i+1,右孩子的编号为 2 i + 2 2i+2 2i+2;
- 假设节点 x x x 的编号为 i i i,且存在父节点,则其父节点的编号为 ⌊ ( i − 1 ) / 2 ⌋ \lfloor (i-1)/2 \rfloor ⌊(i−1)/2⌋。
以下以最小堆为例。
3. 插入
假设待插入的 entry 为 e e e。
(1)首先在堆尾之后的一个位置插入一个新节点,并存储
e
e
e;
(2)假设当前节点为
x
x
x(初始时,
x
x
x 为尾后节点),其父节点为
p
p
p;
(3)如果
p
.
e
n
t
r
y
≤
x
.
e
n
t
r
y
p.entry \le x.entry
p.entry≤x.entry,则成功返回;否则,
(4)上滤:如果
x
.
e
n
t
r
y
<
p
.
e
n
t
r
y
x.entry \lt p.entry
x.entry<p.entry,则令
x
.
e
n
t
r
y
x.entry
x.entry 和
p
.
e
n
t
r
y
p.entry
p.entry 互换位置,然后令
x
x
x 指向
p
p
p,令
p
p
p 指向
p
p
p 的父节点,接着回到步骤(3)。
4. 删除
待删除的 entry 总是位于堆顶。
(1)首先,交换堆顶和堆尾的 entry,然后将堆的大小减一(堆尾前移),以删除堆顶元素(被删除的元素位于堆尾之后的一个位置);
(2)令当前节点为
p
p
p(初始时,
p
p
p 为堆顶);
(3)令
x
x
x 为
p
p
p 的两个孩子节点中较小的一个;
(4)如果
p
.
e
n
t
r
y
≤
x
.
e
n
t
r
y
p.entry \le x.entry
p.entry≤x.entry,则成功返回;否则,
(5)下滤:如果
x
.
e
n
t
r
y
<
p
.
e
n
t
r
y
x.entry \lt p.entry
x.entry<p.entry,则令
x
.
e
n
t
r
y
x.entry
x.entry 和
p
.
e
n
t
r
y
p.entry
p.entry 互换位置,然后令
p
p
p 指向
x
x
x,接着回到步骤(3)。
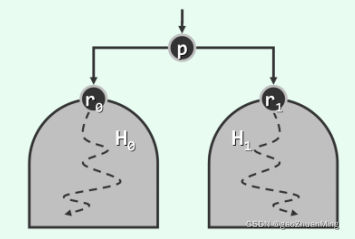
5. 建堆
如下图所示,假设 H 0 , H 1 H_0, H_1 H0,H1 是两个最小堆,现欲将节点 p p p 和最小堆 H 0 , H 1 H_0,H_1 H0,H1 合并为一个新的最小堆。
所需操作是:
(1)令
H
0
H_0
H0 为
p
p
p 的左孩子,
H
1
H_1
H1 为
p
p
p 的右孩子;
(2)接着,从
p
p
p 开始执行下滤操作即可。
因此,给定一个数组,其大小为
n
n
n,现欲使用它构建一个最小堆所需的操作为:
(1)设当前节点为
x
x
x,其节点编号为
m
m
m,初始时,
x
x
x 为堆的最后一个内部节点,编号为
m
←
⌊
(
n
−
2
)
/
2
⌋
m \leftarrow \lfloor (n-2)/2 \rfloor
m←⌊(n−2)/2⌋;
(2)如果
m
<
0
m \lt 0
m<0,则返回;否则,从
x
x
x 开始执行下滤操作(先将子树
x
x
x 转换为一个最小堆);
(3)接着将
x
x
x 指向前一个内部节点,其编号为
m
←
m
−
1
m \leftarrow m-1
m←m−1,然后回到步骤(2)。
上述建堆操作的时间复杂度为 O ( n ) O(n) O(n)。
6. 堆排序
总体而言,堆排序的过程为:对堆执行 n n n 次删除操作,因此其时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。
因为每次删除操作都会将被删除的堆顶元素放到堆尾,而且堆的大小也在不断地减一(堆尾随之不断地向前移动),因此,最后的数组将包含排序后的元素。